Monitoring Impacts of Natural Hazards Using Natural Language Processing
Monitoring Impacts of Natural Hazards Using Natural Language Processing
Understanding how natural hazards affect societies across different sectors is critical for developing effective adaptation strategies and early warning systems. Yet, data on these impacts remain scarce. In my academic research, I use natural language processing (NLP) to extract impact information from large collections of text, such as news articles, reports, and official documents.
Research Highlights
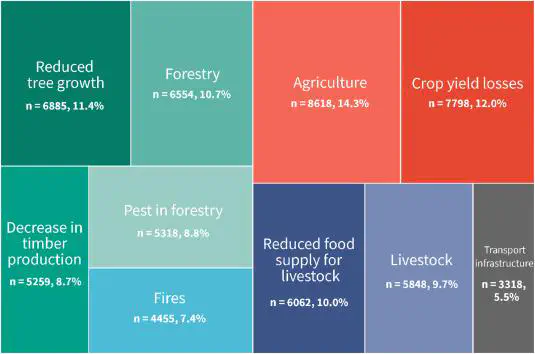
During my doctoral studies, I developed the first automated data pipeline for assessing multi-sector drought impacts from newspaper articles. This approach identifies when and where an impact is reported, supporting the creation of structured impact databases.
We also applied this methodology to monitor flood impacts in Germany during the severe 2021 events, showcasing the adaptability of our NLP framework across hazard types.
Technical Approach
The NLP pipeline integrates several methods:
- Named Entity Recognition (NER)
- Supervised Classification
- Topic Modeling
- Tokenization & Stemming
Together, these components form a robust workflow that transforms unstructured text into actionable, geolocated impact data.
Ongoing Work
More recently, we are incorporating large language models (LLMs) and deep learning to extract more granular and context-rich impact information. We are also expanding beyond news media to include disaster reports, parliamentary documents, and other institutional sources.
Open Science
All code and datasets related to these projects are publicly available.